The Real Matrix
- In the blockbuster movie The Matrix, the machines found a way to harvest human beings.
- Today it's quite the opposite.

In the blockbuster movie, The Matrix, the machines found a way to harvest the bioelectric energy of humans who are enslaved and grown in pods. Like all good science fiction, the concept requires a stretch of one's imagination. However, today there is an inverted parallel -- humans are harvesting the processing power of millions of machines connected to a matrix we call the Internet.
Resources Exist Behind Locked Doors
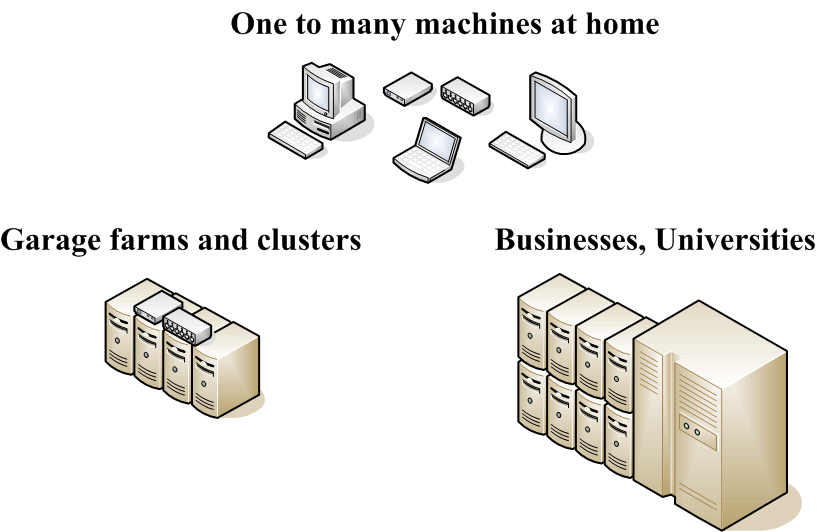
Distributed computing resources can be found in many locations. However, each location has at least one thing in common. People. People, control access to these resources. To paraphrase the Matrix: They are the gate keepers. They are guarding all the doors; they are holding all the keys.
Resources Exist Behind Locked Doors
One to many machines at home
- Connected directly to DSL/Cable modem
- Connected to network switch to DSL/Cable modem
- Each machine is capable of independently communicating with the outside world

Conservative estimates indicate that there are roughly 800 million personal computers in use. About 150 million are Internet connected machines which are expected to increase to one billion by the year 2015. Today, many homes contain more than one machine, often connected via a private home network. In addition an increasing number of machines are connected via broadband, always on, connections.
Resources Exist Behind Locked Doors
Garage farms and clusters
- Multiple machines forming a server farm
- Often used to participate in one or more DC projects
- Each machine typically has Internet access

Some computing enthusiasts go so far as to build and operate their own clusters. The numbers of people who actually do this are larger than you might think! There exists an Internet sub-culture of enthusiasts who refer to themselves as DC'ers. They form and participate in distributed computing teams some of which consists of thousands of individual members.
The Volunteer Computing Model
Public computers support project servers
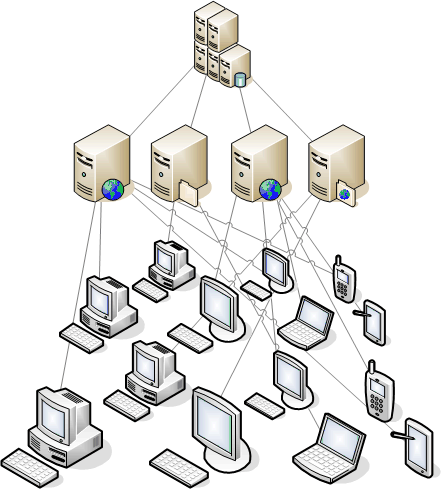
Let’s take a look at how volunteer computing projects actually work. Fundamentally, users download and install a relatively small client application which is capable of communicating with project servers to retrieve individual work units. Each unit of work contains the data - and in some cases - the instructions that a client node can use to process the work. Upon completion the client application sends the results of the work unit to a project server. A project server is responsible for collecting results and performing any post processing that may be required. Compiled results are stored in backend databases. A project server may in turn use the processed results to determine how to generate newer work units for subsequent distribution.
BOINC Architecture
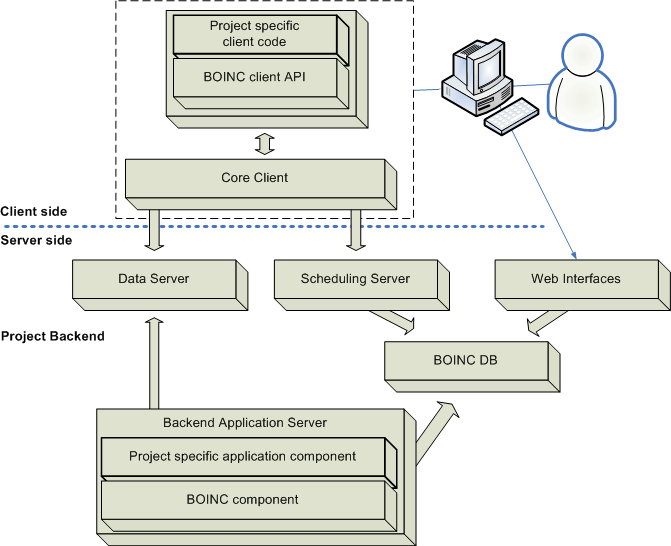
As a BOINC project developer one is only responsible for creating the client-side and server-side behavior that addresses a specific project’s needs. The BOINC framework contains clearly designated areas where one is responsible for adding project specific code modules. The development platform consists of GNU C++ on the server side, and GNU C++ or Microsoft Visual Studio / .NET on the client side. The server environment is expected to be a Linux box with MySQL, Apache and Python installed. The BOINC server side solution utilizes the MySQL database server to store and retrieve project specific information such as work units, results and user accounts. This diagram shows a user interacting with the BOINC system. The client side components are shown to reside in the user’s machine.
Below the client-server separator line we see the components of the BONIC backend. The two bold boxes represent the location of client and server project specific modules. As you can see, BOINC provides a great deal to the project developer. I feel compelled to point out that BOINC’s advantages will very likely outweigh the disadvantages we’ll list in this next section. Keep in mind that BOINC is evolving to meet emerging needs. Visit the project website to learn of new developments.
During the development of the new ChessBrain II project we identified the following issues while investigating BOINC.
- Despite BOINC’s tool support, project developers need to understand and feel comfortable with a number of technologies in order to gain control over their project. In short, BOINC doesn’t yet offer out-of-the box supercomputing - although, at this time it comes closer than any non-commercial tool in existence.
- Complete reliance on LAMP excludes MS Windows environments.
- The BOINC project is structured in the traditional view of client / server architectures. We feel that a P2P view is the emerging future of volunteer computing efforts.
- Uses XML over HTTP which may result in larger communication packets than some project developers may desire.
- End user machines are seen as compute nodes. We feel that volunteer computing projects will need to increasingly embrace server farms, Beowulf clusters and Grid systems.
According to project leader Dr. Anderson, BOINC was specifically created for scientists - not software developers and IT professionals. The goal of BOINC is to enable scientists to easily create volunteer computing projects to meet their growing needs for computational resources. Toward this end, BOINC is a remarkable achievement which will continue to have a profound impact on the future of scientific research.
The ChessBrain II Project
I'd like to speak to you a bit about the ChessBrain project and share with you some of the exciting developments we have planned. ChessBrain is a volunteer computing project which is able to play the game of chess against a human or autonomous opponent while using the processing capabilities of thousands of remote machines. ChessBrain made its public debut during a World Record attempt in here in Copenhagen In January 2004, during a live game against top Danish Chess Grandmaster, Peter Heine Nielsen.
What makes ChessBrain unique is that unlike other volunteer-based computing projects, ChessBrain must receive results in real-time. Failure to receive sufficient results within a specified time will result in weaker play. Tournament games are played using digital chess clocks where the time allotted per game is preset and not renegotiable. so while ChessBrain waits for results its clock is ticking.
Our goal on ChessBrain has been to create a massively distributed virtual supercomputer which uses the game of chess to demonstrate speed-critical distributed computation. We chose chess because of the parallelizable nature of its game tree analysis, and because of our love for the game. This makes the project professionally rewarding as well as personally enjoyable.
The existing design of ChessBrain features a single Intel P4 3 Ghz machine. The machine hosts a database, the ChessBrain Supernode server software and a chess game server. During the exhibition game against Grandmaster Nielsen the machine was overloaded as it tried to support thousands of remote PeerNode clients. Prior to the event we speculated that perhaps a thousand machines might support the chess match. We were not expecting thousands of machines. Fortunately, ChessBrain made it through the match securing a draw on move 34. We've learned a great deal during and after the event. Our improved understanding is being applied on ChessBrain II.
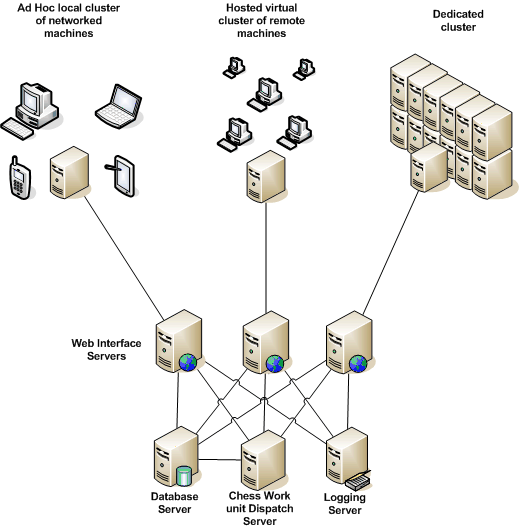
Perhaps the single biggest change with ChessBrain II is that we're replacing the idea of a single SuperNodewith the concept of clusters of SuperNodes that can consist of several thousand PeerNodes. Our vision is to see SuperNodes establish P2P relationships among collaborating SuperNodes. The software for each SuperNode is being designed to create communities of machines, where each community can consist of thousands of machines.
During the game against Grandmaster Nielsen several clusters consisting of over 200 machines, and a few others consisting of 50-100 machines, participated during the event. At the time ChessBrain wasn't designed to take advantage of clusters - like current volunteer computing projects, ChessBrain was designed for use on individual machines. Over time it became clear that ChessBrain software would have to embrace a wider spectrum of computing environments which include Beowulf clusters, compute farms and Grids.
Our vision for ChessBrain has evolved toward P2P distributed clusters, where volunteer computing enthusiasts are promoted to virtual cluster operators. In the parlance of graph theory our goal has become to create more hubs.
Promoting volunteer computing enthusiasts to virtual cluster operators is non-trivial. If we opted for a BOINC-like framework we would have to expect that each cluster operator would be knowledgeable in the use of open source tools such as MySQL and Apache. This simply isn't practical. On the ChessBrain project our Microsoft Windows based contributors outnumber our Linux contributors two to one. We quickly realized that our new SuperNdoe software would have to be a self contained product which can cluster local or remote machines with ease. The new SuperNode software is being built on top of msgcourier in order to address the challenges we're facing on ChessBrain II.
The msgCoureir is a hybrid application consisting of built-in components that enable P2P messaging for distributed computing applications. The msgcourier is being developed as an open source project which isn’t only intended to support next generation volunteer computing but also a host of other potential applications. In this diagram, each server box with connecting lines will run a msgCourier server.
msgCourier
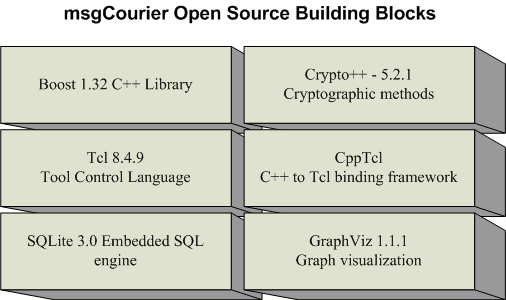
We've leveraged a number of free and open source components to create a robust server application. In support of C++ we use the Boost programming library. We added scripting support to msgcourier by embedding the Tcl language interpreter. We use the C++/Tcl project's software to bind C++ and Tcl. for our database needs we've embedded the SQLite SQL engine into msgCourier. We're securing msgCourier communication using the Crypro++ library. for our network monitoring needs we're using the AT&T Research GraphVis graph visualization software. When using these components msgcourier is under two megabytes in size under Windows and about three megabytes under Linux. The cost of using these libraries really amounts to a more complex build process, but eliminates runtime dependencies.
msgCourier
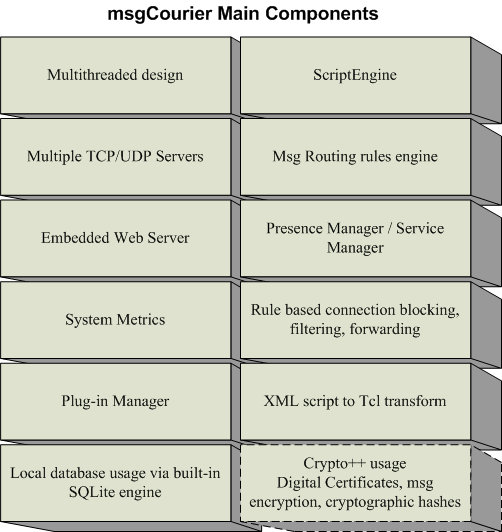
We built msgcourier as a multithreaded application with support for both TCP and UDP based messaging. Messages inside of msgCourier are handled by loadable components called message handlers. The msgCourier server can be configured to route messages to specific handlers on a local machine or to another remote server. This diagram shows a list of components present in the current msgCourier application. The crypto usage box on the bottom right is only currently partially implemented. The msgCourier server has a built-in multi-threaded multiple connection web server component. Application developers can leverage the built-in web server to create their own custom configuration and monitor pages or web based services. The use of HTTP and XML over TCP is optional. However, msgCourier has internal support for HTTP and XML because of their widespread ubiquity and ability to flow through firewall and proxy servers. Let's take a look at a live demonstration of msgcourier.
msgCourier hosted web pages
The DistributedChess.net website is currently being hosted on top of a msgCourier server.
msgCourier hosted web pages
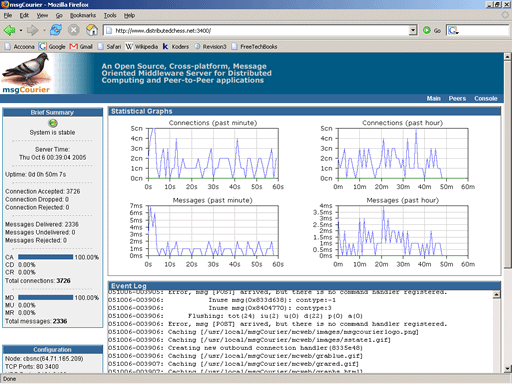
If we point to distributedchess.net and specify port 3400 we're able to access the msgCourier console. Here we see server status information including graphs showing the number of connections per minute and per hour along with the number of messages served during that time.
msgCourier hosted web pages
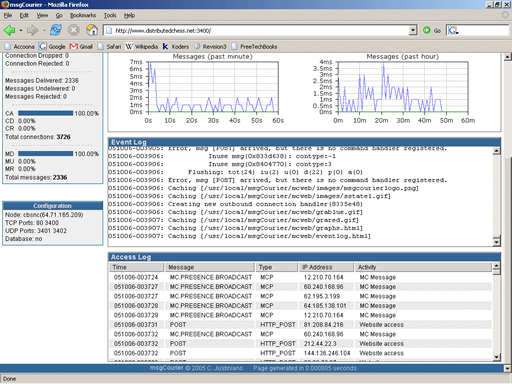
Below the graphs we see the system event log which allows an operator to peer into the server's inner workings. If we scroll the page we can see an access log showing the type of messages that are being sent and received.
msgCourier hosted web pages
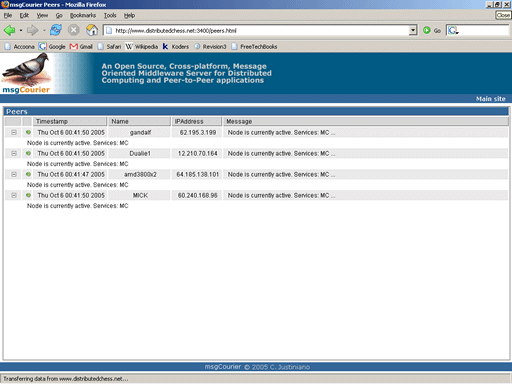
This next screen shows a list of connected Supernodes. Each nodes information can be expanded and collapsed for viewing. msgCourier is currently undergoing its first public review testing. The framework for many of the features we've described is already in place and quickly evolving. We invite you to learn more about msgCourier on msgcourier.com. Keep in mind that its still very early in its development.